ロボティクスと機械学習の融合領域である「ロボット学習」に取り組んでいます. 特に, エージェントが環境と相互作用しながらタスクを達成するための最適な行動を学習する強化学習を中心に, 実環境で機能する方策の学習と, 複数方策を活用した高効率な学習に関する研究を進めています. , 課外活動やパートタイマーとして, ロボットによる自動化やコンピュータビジョン技術の社会実装のための研究・開発に取り組んでいます.
Rethinking Policy Diversity in Ensemble Policy Gradientin Large-Scale Reinforcement Learning
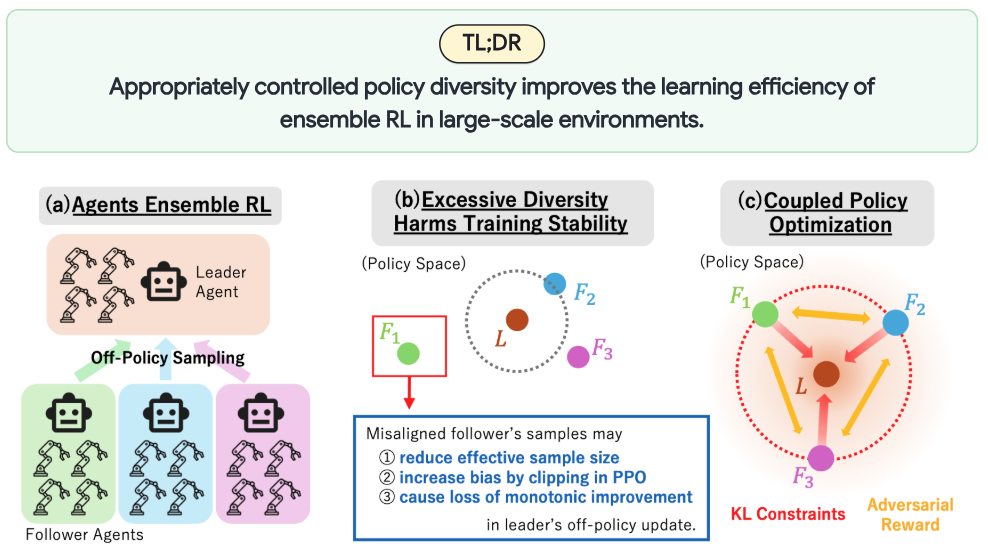
数万規模の並列環境を用いる大規模強化学習では, 従来の強化学習とは異なる学習ダイナミクスが生じます. 近年は, 複数の方策を同時に学習して多様なデータを収集する手法が研究されています. 本研究では, これらの方策間の多様性をどのように構造化し, 制御すべきかを注目しました.
理論解析と実験の両面から, 方策多様性は常に有益ではなく, 方策間の過度な乖離が学習安定性とサンプル効率を損なうことを示しました. その上で, 方策間 KL ダイバージェンスを制御し, フォロワー方策がリーダー方策の近傍を効率よく探索する Coupled Policy Optimization を提案しました. 提案手法は多指ハンド物体操作を含む難しいタスクで, SAPG, PBT, PPO などの強力なベースラインを上回る性能を示しました.
Katakko: Embodiment of Modular Robotsthrough Automatic Motion Mapping
Emerging Technologies

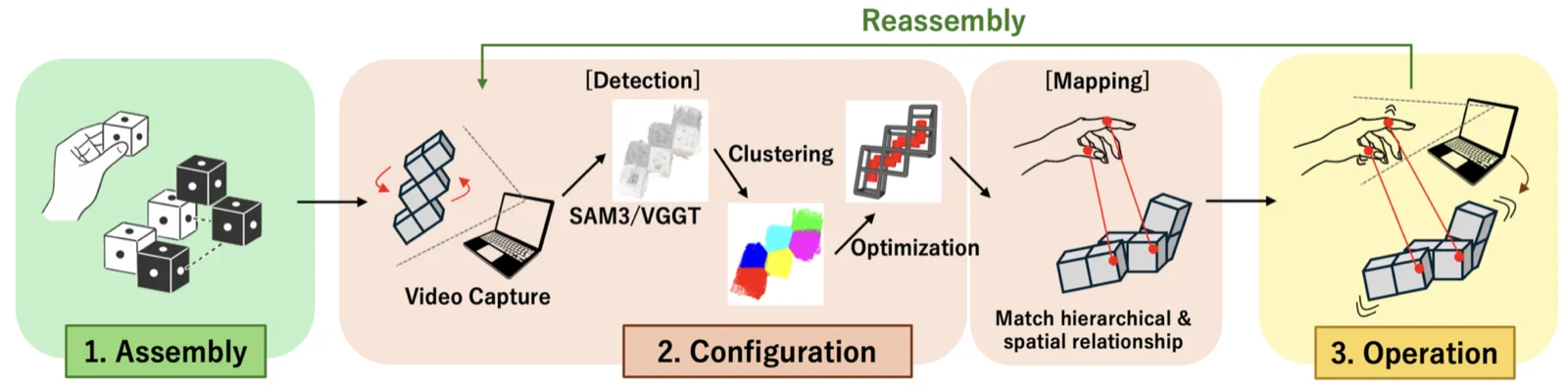
Katakko は, ユーザが工学的な専門知識を持たなくても, 個人化されたソーシャルエージェントを作り身体化できるモジュール型ロボットシステムです. 機能モジュールと, 人の動きを任意に組み立てられたロボット構造へ自動対応付けするフレームワークを導入しています. 画像からロボット構成を検出し, 構造的な対応関係に基づいて関節間のマッピングを生成し, 組み替え後も制御の一貫性を保つための増分更新を支援します.
私は自動モーションマッピング生成とロボット構造認識に取り組みました.
MITOH Page SIGGRAPH Official X Post Conference Page
Gaussians in the City: Enhancing 3D Scene Reconstructionunder distractors with Text-guided Segmentation and Inpainting
Poster Track
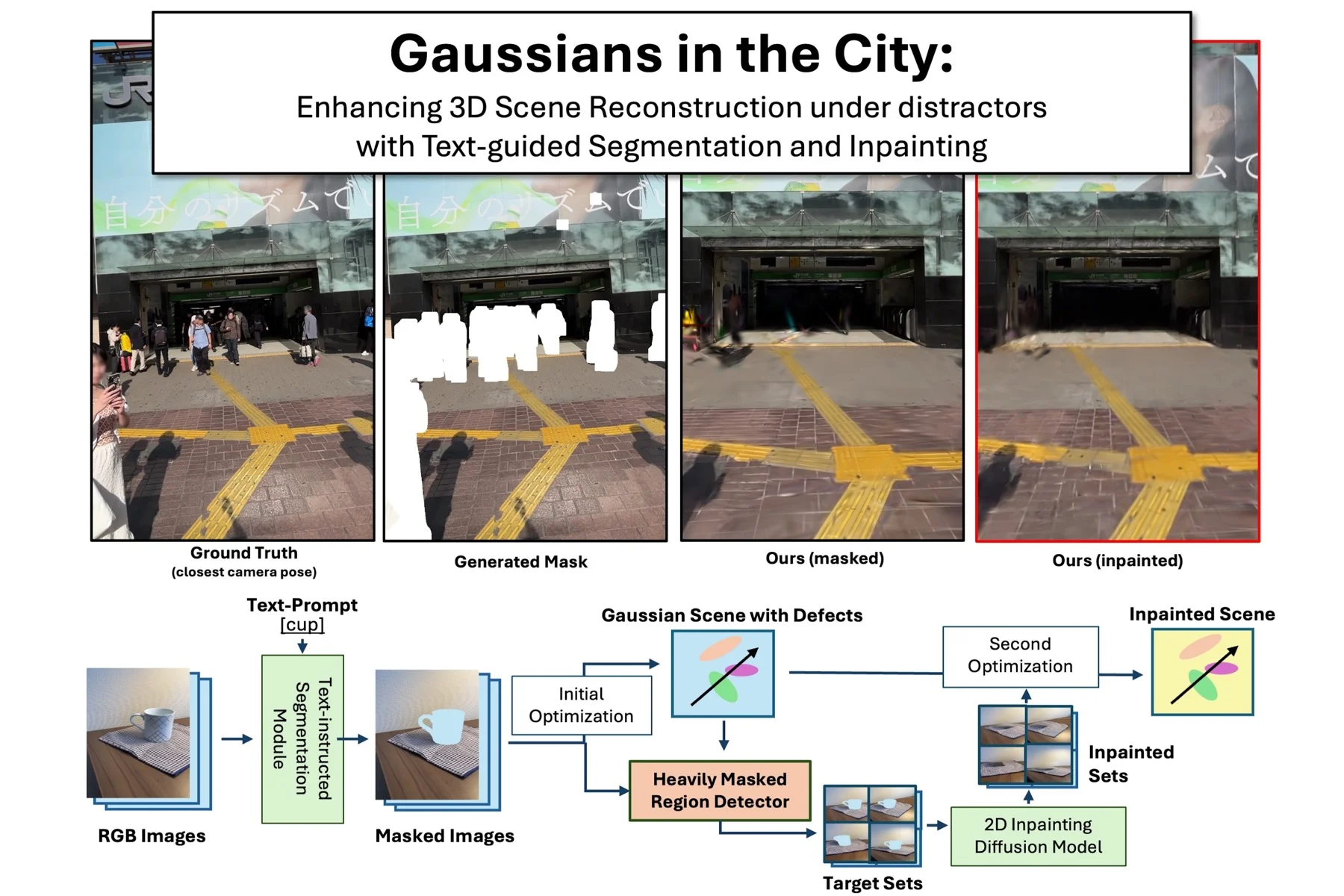
NeRF や 3D Gaussian Splatting を用いた3次元シーン再構成では, 実世界データに歩行者や車両などの動的・静的な障害物が含まれることが多く, 再構成品質を低下させます. 既存手法はクリーンなシーンを仮定したり, 不完全なマスク処理に依存したりするため, 特に強く遮蔽された領域でアーティファクトが生じやすいという課題があります.
本研究では, このような難しい条件下で頑健にシーンを再構成する方法を検討しました. 非常に混雑した環境において障害物を単にマスクするだけでは, 観測が欠落した領域に欠陥が生じることを示し, テキストベースのセグメンテーションと選択的な画像補完を組み合わせる手法を提案しました. 提案手法は強くマスクされた領域を検出し, 必要な箇所にのみ3次元的に一貫した補完を適用することで, 全体の整合性を保ちながらアーティファクトを低減します.
Food Manipulation Competition
Competition
(ICRA2023 ViTac WS)
さまざまな食品を対象とした Pick & Place タスクにおいて, 深度情報に基づく食品のインスタンス認識と把持姿勢推定に取り組みました.