My research lies at the intersection of robotics and machine learning, with a focus on reinforcement learning. I study how to learn policies that work in real-world robotic systems and how to improve data efficiency by leveraging policy ensembles in large-scale training settings. Through hobby projects and part-time work, I also work on research and development for deploying robotic automation and computer vision technologies in real-world applications.
Rethinking Policy Diversity in Ensemble Policy Gradientin Large-Scale Reinforcement Learning
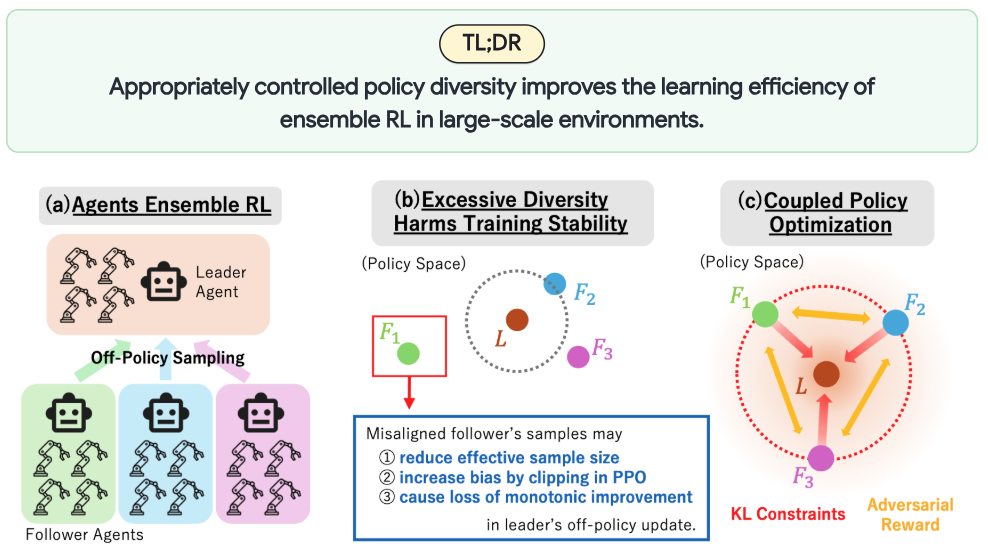
In large-scale RL with tens of thousands of parallel environments, the learning dynamics differ from traditional RL settings. Recent work has therefore explored learning multiple policies together to collect diverse data. In this work, we investigate how the diversity between these policies should be structured and controlled.
Through both theoretical and empirical analyses, we show that policy diversity is not always beneficial: excessive divergence between policies can harm training stability and sample efficiency. To address this issue, we propose Coupled Policy Optimization, which regulates inter-KL divergence to encourage follower policies to perform efficient exploration around the leader policy. Our method achieves significantly improved final performance and sample efficiency on challenging tasks such as dexterous manipulation, outperforming strong baselines including SAPG, PBT, and PPO.
Katakko: Embodiment of Modular Robotsthrough Automatic Motion Mapping
Emerging Technologies

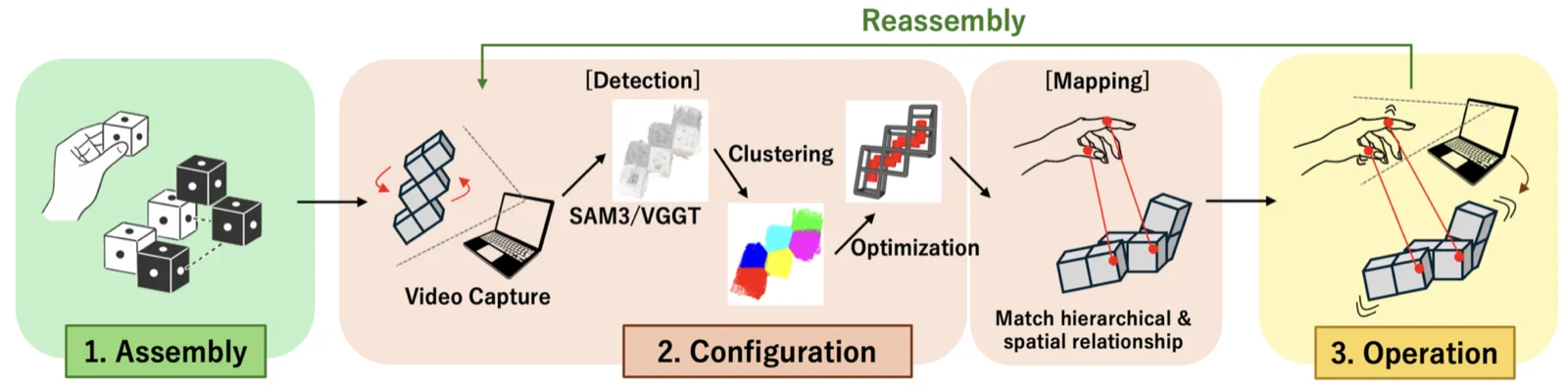
Katakko is a modular robot system for creating and embodying personalized social agents without requiring engineering ability for users. It introduces functional modules and an automatic framework that maps human motion to arbitrarily assembled robot structures. The system detects robot configurations via pictures and generates joint-to-joint mappings based on structural alignment, with support for incremental updates to preserve control consistency.
I worked on automatic motion mapping generation and robot structure recognition.
MITOH Page (Japanese only) SIGGRAPH Official X Post Conference Page
Gaussians in the City: Enhancing 3D Scene Reconstructionunder distractors with Text-guided Segmentation and Inpainting
Poster Track
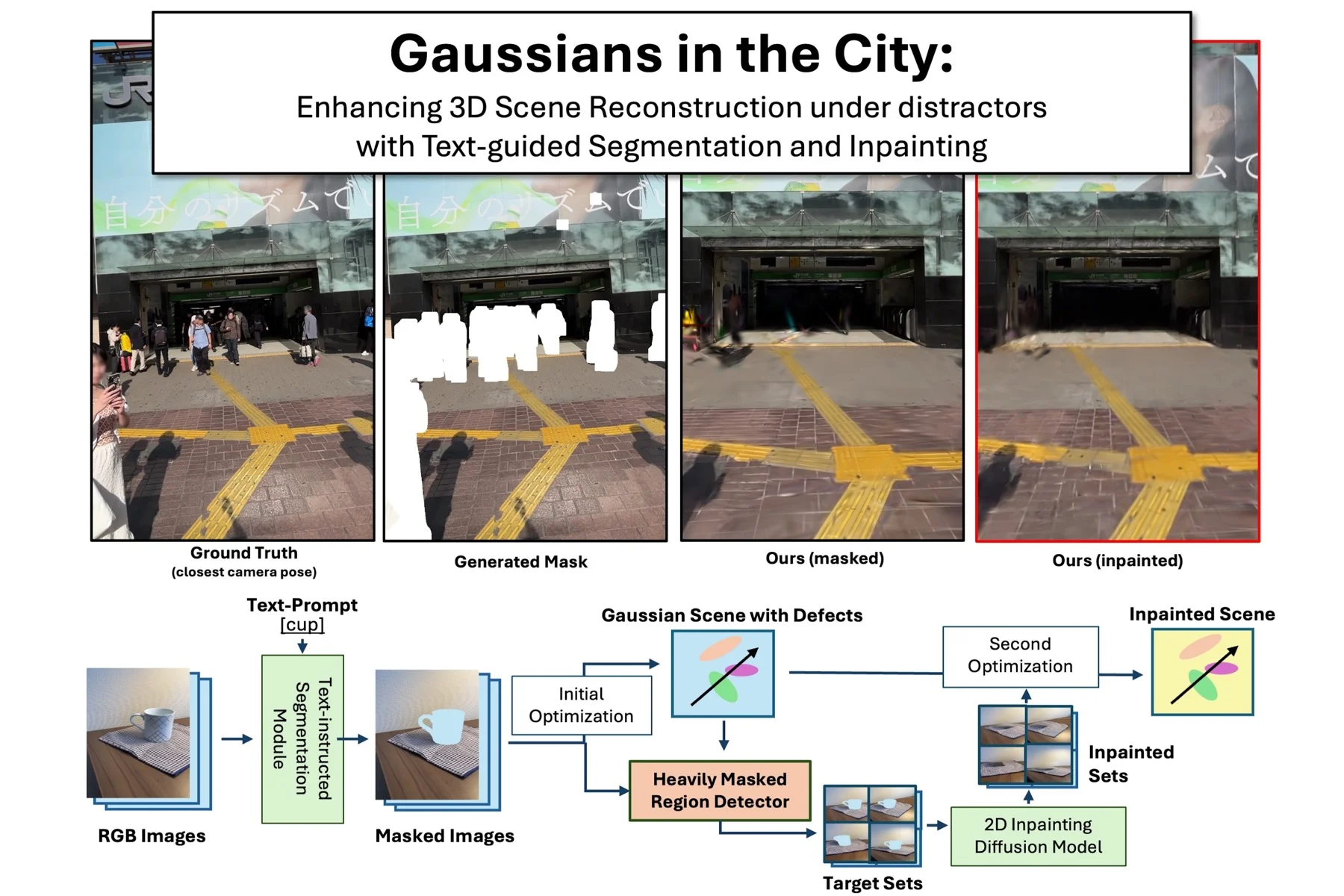
In 3D scene reconstruction using NeRF and 3D Gaussian Splatting, real-world data often contains both dynamic and static distractors, such as pedestrians and vehicles, which degrade reconstruction quality. Existing approaches typically assume clean scenes or rely on imperfect masking strategies, leading to artifacts especially in heavily occluded regions.
In this work, we investigate how to robustly reconstruct scenes under such challenging conditions. We show that simply masking distractors is insufficient, as it introduces defects in regions with missing observations. To address this, we propose a method that combines text-guided segmentation with selective inpainting. Our approach identifies heavily masked regions and applies 3D-consistent inpainting only where necessary, preserving overall consistency while reducing artifacts.
Food Manipulation Competition
Competition
(ICRA2023 ViTac WS)
In a robot competition involving pick-and-place tasks for various food items, I worked on instance recognition of the food and grasp pose estimation based on depth information.